Download the pdf here .
Saturday 17 November 2012
Tuesday 2 October 2012
THREE LEVEL ARCHITECTURE
For the system to be usable, it must retrieve data efficiently. The need for efficiency has led designers to use complex data structures to represent data in the database. Since many database-systems users are not computer trained, developers hide the complexity from users through several levels of abstraction, to simplify users’ interactions with the system:
• Conceptual View (Global or community user view)
• Internal level (physical or storage view).
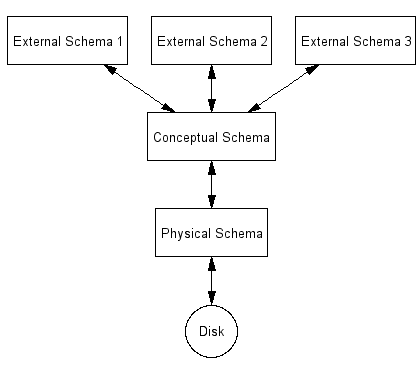
OBJECTIVES OF THREE LEVEL ARCHITECTURE:
The database views were suggested because of following reasons or objectives of levels of a database:
1. Make the changes easy in database when some changes needed by environment.
2. The external view or user views do not depend upon any change made ii other view. For example changes in hardware, operating system or internal view should not change the external view.
3. The users of database should not worry about the physical implementation and internal working of database system.
4. The data should reside at same place and all the users can access it as per their requirements.
5. DBA can change the internal structure without effecting the user’s view.
6. The database should be simple and changes can be easily made.
7. It is independent of all hardware and software.
External/View level
The highest level of abstraction where only those parts of the entire database are included which are of concern to a user. Despite the use of simpler structures at the logical level, some complexity remains, because of the large size of the database. Many users of the database system will not be concerned with all this information. Instead, such users need to access only a part of the database. So that their interaction with the system is simplified, the view level of abstraction is defined. The system may provide many views for the same database.
Databases change over time as information is inserted and deleted. The collection of information stored in the database at a particular moment is called an instance of the database. The overall design of the database is called the database schema. Schemas are changed infrequently, if at all.
Database systems have several schemas, partitioned according to the levels of abstraction that we discussed. At the lowest level is the physical schema; at the intermediate level is the logical schema and at the highest level is a subschema.
The features of this view are
• The external or user view is at the highest level of database architecture.
• Here only one portion of database will be given to user.
• One portion may have many views.
• Many users and program can use the interested part of data base.
• By creating separate view of database, we can maintain security.
• Only limited access (read only, write only etc) can be provided in this view.
For example: The head of account department is interested only in accounts but in library information, the library department is only interested in books, staff and students etc. But all such data like student, books, accounts, staff etc is present at one place and every department can use it as per need.
Conceptual/Logical level
Database administrators, who must decide what information is to be kept in the database, use this level of abstraction. One conceptual view represents the entire database. There is only one conceptual view per database.
The description of data at this level is in a format independent of its physical representation. It also includes features that specify the checks to retain data consistence and integrity.
The features are:
• The conceptual or logical view describes the structure of many users.
• Only DBA can be defined it.
• It is the global view seen by many users.
• It is represented at middle level out of three level architecture.
• It is defined by defining the name, types, length of each data item. The create table
commands of Oracle creates this view.
• It is independent of all hardware and software.
Internal/Physical level
The lowest level of abstraction describes how the data are stored in the database, and what relationships exist among those data. The entire database is thus described in terms of a small number of relatively simple structures, although implementation of the simple structures at the logical level may involve complex physical-level structures, the user of the logical level does not need to be aware of this complexity.
The features are :
• It describes the actual or physical storage of data.
• It stores the data on hardware so that can be stored in optimal time and accessed
in optimal time.
• It is the third level in three level architecture.
• It stores the concepts like:
• B-tree and Hashing techniques for storage of data.
• Primary keys, secondary keys, pointers, sequences for data search.
• Data compression techniques.
• It is represented as
FILE EMP [
INDEX ON EMPNO
FIELD = {
(EMPNO: BYTE (4),
ENAME BYTE(25))]
Mapping between views
• The conceptual/internal mapping:
o defines conceptual and internal view correspondence
• specifies mapping from conceptual records to their stored counterparts
o An external/conceptual mapping:
• defines a particular external and conceptual view correspondence
• A change to the storage structure definition means that the conceptual/internal
mapping must be changed accordingly, so that the conceptual schema may remain
invariant, achieving physical data independence.
• A change to the conceptual definition means that the conceptual/external mapping
must be changed accordingly, so that the external schema may remain invariant,
achieving logical data independence.
KEYS
Keys are, as their name suggests, a key part of a relational database and a vital part of the structure of a table. They ensure each record within a table can be uniquely identified by one or a combination of fields within the table. They help enforce integrity and help identify the relationship between tables. There are three main types of keys, candidate keys, primary keys and foreign keys. There is also an alternative key or secondary key that can be used, as the name suggests, as a secondary or alternative key to the primary key.
Super Key:
A Super key is any combination of fields within a table that uniquely identifies each record within that table.
Candidate Key:
A candidate is a subset of a super key. A candidate key is a single field or the least combination of fields that uniquely identifies each record in the table. The least combination of fields distinguishes a candidate key from a super key. Every table must have at least one candidate key but at the same time can have several.
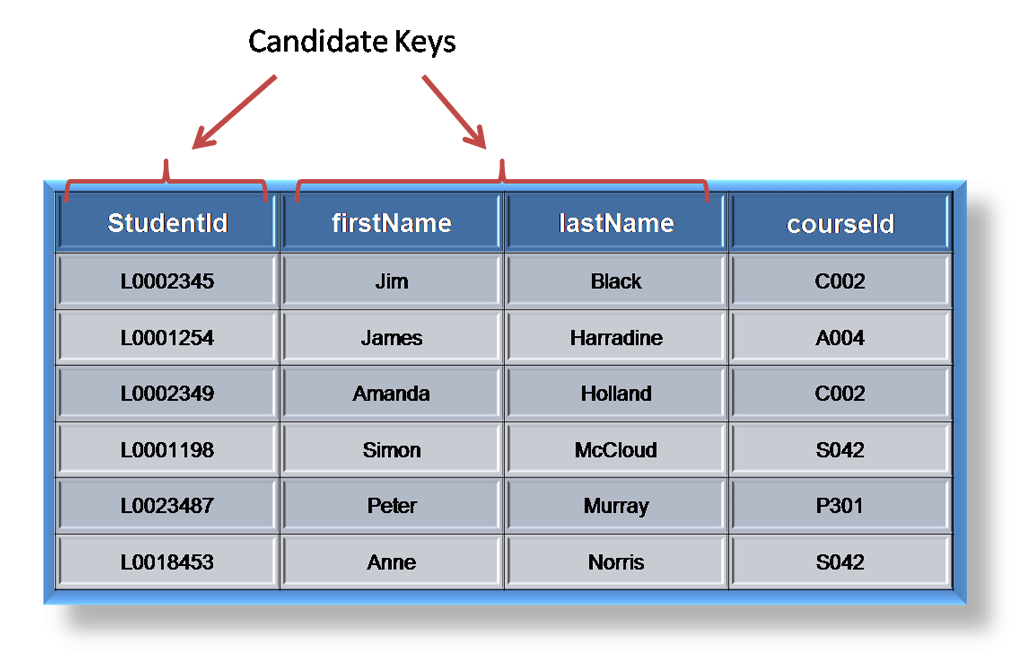
As an example we might have a student_id that uniquely identifies the students in a student table. This would be a candidate key. But in the same table we might have the student’s first name and last name that also, when combined, uniquely identify the student in a student table. These would both be candidate keys.
In order to be eligible for a candidate key it must pass certain criteria.
Once your candidate keys have been identified you can now select one to be your primary key.
Primary Key:
A primary key is a candidate key that is most appropriate to be the main reference key for the table. As its name suggests, it is the primary key of reference for the table and is used throughout the database to help establish relationships with other tables. As with any candidate key the primary key must contain unique values, must never be null and uniquely identify each record in the table.
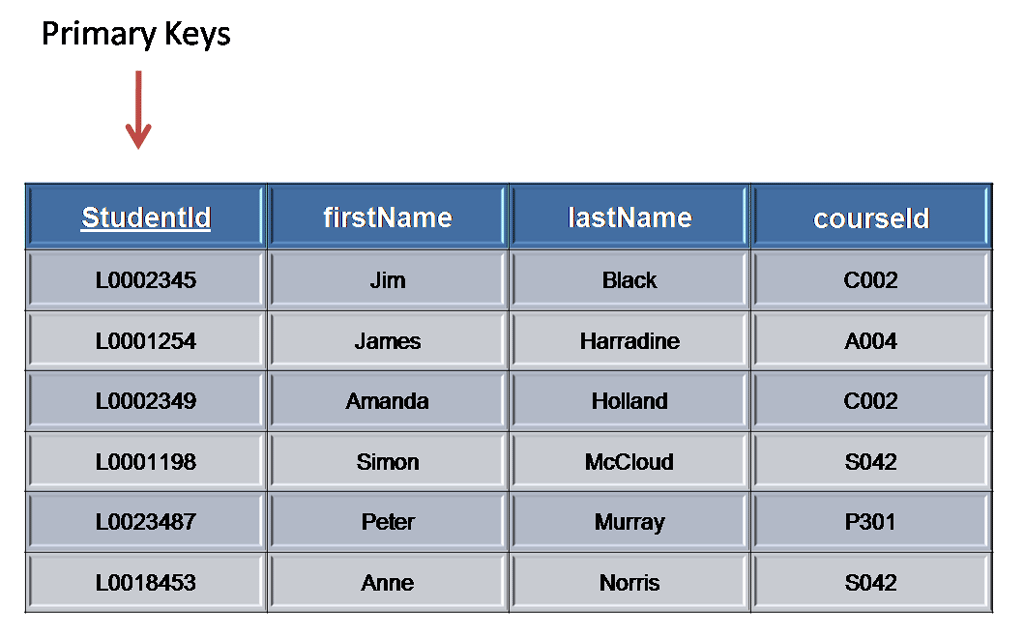
As an example, a student id might be a primary key in a student table, a department code in a table of all departments in an organisation. In the table above we have selected the candidate key student_id to be our most appropriate primary key
Primary keys are mandatory for every table each record must have a value for its primary key. When choosing a primary key from the pool of candidate keys always choose a single simple key over a composite key.
Foreign Key:
A foreign key is generally a primary key from one table that appears as a field in another where the first table has a relationship to the second. In other words, if we had a table A with a primary key X that linked to a table B where X was a field in B, then X would be a foreign key in B.
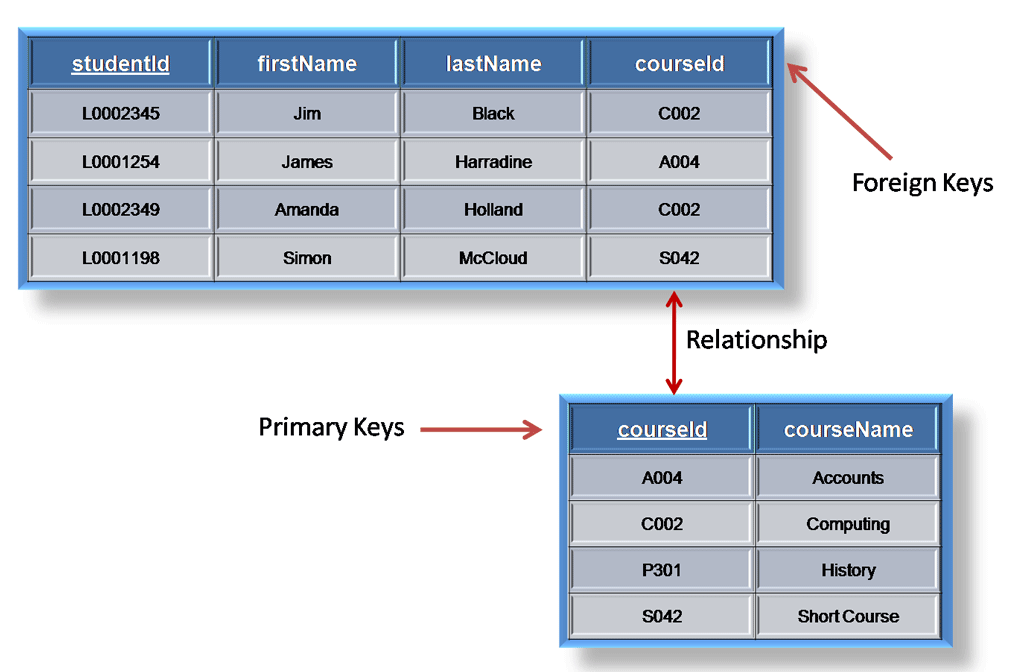
An example might be a student table that contains the course_id the student is attending. Another table lists the courses on offer with course_id being the primary key. The 2 tables are linked through course_id and as such course_id would be a foreign key in the student table.
Super Key:
A Super key is any combination of fields within a table that uniquely identifies each record within that table.
Candidate Key:
A candidate is a subset of a super key. A candidate key is a single field or the least combination of fields that uniquely identifies each record in the table. The least combination of fields distinguishes a candidate key from a super key. Every table must have at least one candidate key but at the same time can have several.
As an example we might have a student_id that uniquely identifies the students in a student table. This would be a candidate key. But in the same table we might have the student’s first name and last name that also, when combined, uniquely identify the student in a student table. These would both be candidate keys.
In order to be eligible for a candidate key it must pass certain criteria.
- It must contain unique values
- It must not contain null values
- It contains the minimum number of fields to ensure uniqueness
- It must uniquely identify each record in the table
Once your candidate keys have been identified you can now select one to be your primary key.
Primary Key:
A primary key is a candidate key that is most appropriate to be the main reference key for the table. As its name suggests, it is the primary key of reference for the table and is used throughout the database to help establish relationships with other tables. As with any candidate key the primary key must contain unique values, must never be null and uniquely identify each record in the table.
As an example, a student id might be a primary key in a student table, a department code in a table of all departments in an organisation. In the table above we have selected the candidate key student_id to be our most appropriate primary key
Primary keys are mandatory for every table each record must have a value for its primary key. When choosing a primary key from the pool of candidate keys always choose a single simple key over a composite key.
Foreign Key:
A foreign key is generally a primary key from one table that appears as a field in another where the first table has a relationship to the second. In other words, if we had a table A with a primary key X that linked to a table B where X was a field in B, then X would be a foreign key in B.
An example might be a student table that contains the course_id the student is attending. Another table lists the courses on offer with course_id being the primary key. The 2 tables are linked through course_id and as such course_id would be a foreign key in the student table.
DIFFERENCE BETWEEN PHYSICAL AND LOGICAL DATA INDEPENDENCE
One of the biggest advantages of database is data independence. It means we can change the conceptual schema at one level without affecting the data at other level. It means we can change the structure of a database without affecting the data required by users and program. This feature was not available in file oriented approach. There are two types of data independence and they are:
1. Physical data independence
2. Logical data independence
Data Independence The ability to modify schema definition in on level without affecting schema definition in the next higher level is called data independence. There are two levels of data independence:
1. Physical data independence is the ability to modify the physical schema without causing application programs to be rewritten. Modifications at the physical level are occasionally necessary to improve performance. It means we change the physical storage/level without affecting the conceptual or external view of the data. The new changes are absorbed by mapping techniques.
2. Logical data independence in the ability to modify the logical schema without causing application program to be rewritten. Modifications at the logical level are necessary whenever the logical structure of the database is altered (for example, when money-market accounts are added to banking system).
Logical Data independence means if we add some new columns or remove some columns from table then the user view and programs should not changes. It is called the logical independence. For example: consider two users A & B. Both are selecting the empno and ename. If user B add a new column salary in his view/table then it will not effect the external view user; user A, but internal view of database has been changed for both users A & B. Now user A can also print the salary.
User A’s External View
(View before adding a new column)
User B’s external view
(View after adding a new column salary)
It means if we change in view then program which use this view need not to be changed.
Logical data independence is more difficult to achieve than is physical data independence, since application programs are heavily dependent on the logical structure of the data that they access.
Logical data independence means we change the physical storage/level without effecting the conceptual or external view of the data. Mapping techniques absorbs the new changes.
NETWORK MODEL INTRODUCTION
Each database system uses a approach to store and maintain the data. For this purpose different data models were developed like Hierarchical model, Network Model and Relational Model.
NETWORK MODEL:
The popularity of the network data model coincided with the popularity of the hierarchical data model. Some data were more naturally modeled with more than one parent per child. So, the network model permitted the modeling of many-to-many relationships in data.The basic data modeling construct in the network model is the set construct. A set consists of an owner record type, a set name, and a member record type. A member record type can have that role in more than one set, hence the multiparent concept is supported. An owner record type can also be a member or owner in another set. The data model is a simple network, and link and intersection record types (called junction records by IDMS) may exist, as well as sets between them . Thus, the complete network of relationships is represented by several pairwise sets; in each set some (one) record type is owner (at the tail of the network arrow) and one or more record types are members (at the head of the relationship arrow). Usually, a set defines a 1:M relationship, although 1:1 is permitted. The CODASYL network model is based on mathematical set theory.

Like the hierarchical model, this model uses pointers toward stored data. However, it does not necessarily use a downward tree structure.
NETWORK MODEL:
The popularity of the network data model coincided with the popularity of the hierarchical data model. Some data were more naturally modeled with more than one parent per child. So, the network model permitted the modeling of many-to-many relationships in data.The basic data modeling construct in the network model is the set construct. A set consists of an owner record type, a set name, and a member record type. A member record type can have that role in more than one set, hence the multiparent concept is supported. An owner record type can also be a member or owner in another set. The data model is a simple network, and link and intersection record types (called junction records by IDMS) may exist, as well as sets between them . Thus, the complete network of relationships is represented by several pairwise sets; in each set some (one) record type is owner (at the tail of the network arrow) and one or more record types are members (at the head of the relationship arrow). Usually, a set defines a 1:M relationship, although 1:1 is permitted. The CODASYL network model is based on mathematical set theory.
Like the hierarchical model, this model uses pointers toward stored data. However, it does not necessarily use a downward tree structure.
Thursday 27 September 2012
ER DIAGRAMS TO SQL QUERIES
ONE TO MANY:For any A there are many Bs. For any B there is no more than one A. (Equivalently, there may be one A)
create table B(b_id type,b_name type,<b_other>constraint primary key(b_id));create table A(a_id type,a_name type,b_id type,<a_other>,constraint primary key(a_id),constraint foreign key(b_id) references B);ONE TO MANY WITH TOTAL PARTICIPATION:For any A there are possibly many Bs. For any B, there only one A.create table B(b_id type primary key,b_name type,<b_other>);create table A (a_id type primary key,a_name type,b_id type not null,<a_other>,foreign key (b_id) references B);MANY TO MANY:For any A there are possibly many Bs. For any B there are possibly many As.

create table A
(a_id type, a_name type, <a_other>, primary key (a_id));create table B (b_id type, b_name type, <b_other>, primary key (b_id));create table R (a_id type, b_id type, <r_other>, primary key (a_id, b_id), foreign key (a_id) references A, foreign key (b_id) references B); ONE TO ONE(0-1—0-1):For any A there may be one B. For any B there may be one A

create table A(a_id type,a_name type,<a_other>,primary key (a_id));create table B(b_id type,b_name type,<b_other>,primary key (b_id));create table R (a_id type,b_id type not null,<r_other>,primary key (a_id),foreign key (a_id) references A,foreign key (b_id) references B,unique (b_id));MANY TO ONE:create table A(a_id type,a_name type,<a_other>,primary key (a_id));create table B(b_id type,b_name type,a_id type, type<b_other>,primary key (b_id),foreign key (a_id) references A);AGGREGATE:

This looks like the subtype relationship but it is interpreted differently. Attributes are not “inherited” by the subparts like they are by the subtypes. Suppose we had the following information to store:carid, namebodyid, nameengineid, name create table car (
id type primary key,
name type,
body_id type,
engine_id type,
foreign key (body_id) references body,
foreign key (engine_id) references engine);
create table body
(id type primary key,
name type);
create table engine
(id type primary key,
name type);
WEAK ENTITIES:

These entities exist only when another entity exists.employee(id, name)salhist(Id, revision_date, salary)create table employee (id type primary key,name type);create table salhist (id type,revision_date date,salary number,primary key (id, revision_date),foreign key (id) references employeeon delete cascade);ONE TO ONE (1-1):

For any A there must be one B. For any B there must be one A.create table A
(a_id type,
a_name type,
<a_other>,
primary key (a_id));
create table B
(b_id type,
b_name type,
fk_b_a type not null,
primary key (b_id),
unique (fk_b_a),
foreign key (fk_b_a) references A);
Wednesday 29 August 2012
Practice Assignment
Schema :
Nurse(NID,Name,Bdate,WID)
Function(FID,Fname,Description)
Ward(WID,Wname,Location)
Services(WID,FID)
Certified(NID,FID)
Queries :
1.print names of nurses not assigned to any ward.
2.print the name of the ward for which no nurse is assigned.
3.for each ward print ward name and no.of services it offers.
4.print the ward with maximum no.of nurses assigned.
5.print the names of nurses whose functions are ensured by the ward to which they are assigned.
6.list the wards that offer all services offered by ward w1.
7.print the name of the most certified nurse.
8.print pairs of nurses assigned to same ward.
9.print the name of wards that ensure each function offered by the hospital.
10.print nurse-id of nurses certified for every function the hospital offers.
11.for each ward print ward-id and nurse-id of most certified nurse.
Thursday 2 August 2012
Tuesday 17 July 2012
Birthday Reminder Application

Ever missed a birthday? I did. That's why I created Birthday Reminder to remind myself of when birthdays are coming.
Birthday Reminder is a simple program that remind users of important birthdays.The application helps us to add our friend's birthday, view all the birthdays stored,search for the dearest one's birthday and also to edit them.
By-
- Soma Sneha - 1005-10-733051
- V.Rasagna - 1005-10-733042
- Puranam Srinivas - 1005-10-733054
Thursday 26 April 2012
EVIL HANGMAN
Our assignment is to write a computer program which plays a game of Hangman using this “Evil Hangman” algorithm. In particular, our program will do following:
1. Read the file dictionary.txt, which contains the full contents of the words list.
2. Prompt the user for a word length, reprompting as necessary until he enters a number such that there's at least one word that's exactly that long. That is, if the user wants to play with words of length -42 or 137, since no English words are that long, we should reprompt him.
3. Prompt the user for a number of guesses, which must be an integer greater than zero.
4. Prompt the user for whether he wants to have a running total of the number of words remaining in the word list. This completely ruins the illusion of a fair game that we'll be cultivating.
Evil Hangman algorithm:
1. Constructing list of all words in the English language whose length matches the input length.
2. Printing out how many guesses the user has remaining, along with any letters the player has guessed and the current blanked-out version of the word. If the user chose earlier to see the number of words remaining, print that out too.
3. Prompting the user for a single letter guess, reprompting until the user enters a letter that he hasn't guessed yet.
4. Partitioning the words in the dictionary into groups by word family.
5. Finding the most common “word family” in the remaining words, remove all words from the word list that aren't in that family, and report the position of the letters (if any) to the user. If the word family doesn't contain any copies of the letter, subtract a remaining guess from the user.
6. If the player has run out of guesses pick a word from the word list and display it as the word that the computer initially “chose.”
7. If the player correctly guesses the word, congratulate him.
6. Ask if the user wants to play again and loop accordingly.
We use associative arrays for this purpose.
Monday 2 April 2012
MESSENGER(app) --Problem Decription
Aim: To create an application which can be used to send bulk messages to mobiles on the database.
This is to connect an entire community (class,department or entire college)according to the database option selected.
--helpful to pass information at an instant to a large number of recipients pertaining to a group.
The simple design of the app contains
* a space provided to enter the message to be passed on.
* selection of recipient group.
POSSIBLE UPGRADING:
--Two way communication (COMMUNICATOR instead of MESSENGER)
--> Requirement: A toll free number
** messages go from the communicator;
recipient can reply to a toll free number.
these replies should be displayed in the communicator with the recipients details.
Further development can be planned.
Thursday 15 March 2012
INLINE FUNCTIONS
DEFINITION:
An inline function is one for which the compiler copies the code from the function definition directly into the code of the calling function rather than creating a separate set of instructions in memory. Instead of transferring control to and from the function code segment, a modified copy of the function body may be substituted directly for the function call. In this way, the performance overhead of a function call is avoided.
A function is declared inline by using the inline function specifier or by defining a member function within a class or structure definition. The inline specifier is only a suggestion to the compiler that an inline expansion can be performed; the compiler is free to ignore the suggestion.
The following code fragment shows an inline function definition:
inline int add(int i, int j)
{
return i + j;
}
The use of the inline specifier does not change the meaning of the function. However, the inline expansion of a function may not preserve the order of evaluation of the actual arguments. Inline expansion also does not change the linkage of a function: the linkage is external by default.
In C++, both member and nonmember functions can be inlined. Member functions that are implemented inside the body of a class declaration are implicitly declared inline. Constructors, copy constructors, assignment operators, and destructors that are created by the compiler are also implicitly declared inline. An inline function that the compiler does not inline is treated similarly to an ordinary function: only a single copy of the function exists, regardless of the number of translation units in which it is defined.
In C, any function with internal linkage can be inlined, but a function with external linkage is subject to restriction. . The restrictions are as follows:
• If the inline keyword is used in the function declaration, then the function definition must appear in the same translation unit.
• An inline definition of a function is one in which all of the file-scope declarations for it in the same translation unit include the inline specifier withoutextern.
• An inline definition does not provide an external definition for the function: an external definition may appear in another translation unit. The inline definition serves as an alternative to the external definition when called from within the same translation unit.
In the Ada programming language, there exists a pragma for inline functions. Most other languages, including Java and functional languages, do not provide language constructs for inline functions, but often do perform aggressive inline expansion.
ADVANTAGES:
- It saves the time required to execute function calls.
- Small inline functions, perhaps three lines or less, create less code than the equivalent function call because the compiler doesn't generate code to handle arguments and a return value.
- Functions generated inline are subject to code optimizations not available to normal functions because the compiler does not perform inter procedural optimizations.
DISADVANTAGES:
- Inlining can increase the size of your executable program significantly leading to more number of page faults bringing down program performance..
- If used in header file, it will make your header file size large and may also make it unreadable.
- Macro is expanded by preprocessor and inline function are expanded by compiler.
- Expressions passed as arguments to inline functions are evaluated only once while expression passed as argument to inline functions are evaluated more than once.
- Inline functions are used to overcome the overhead of function calls. Macros are used to maintain the readability and easy maintainence of the code.
- Debugging is tough in macros (because they refer to the expanded code, rather than the code the programmer typed) whereas debugging is easy in inline functions.
- Macro invocations do not perform type checking, or even check that arguments are well-formed, whereas function calls usually do.
- A macro cannot return anything which is not the result of the last expression invoked inside it but in inline functions we can return any value by using keyword return();
Thursday 8 March 2012
SWAPPING IN JAVA
In Java the swap function works if we use wrapped integers and pass references to them to the function. However, the Java wrapper class for int is Integer and it doesn't allow to alter the data field inside. Thus we need our own wrapper class (MyInteger below).
// MyInteger: similar to Integer, but can change value
class MyInteger
{
private int x; // single data member
public MyInteger(int xIn)
{
x = xIn;
} // constructor
public int getValue()
{
return x;
} // retrieve value
public void insertValue(int xIn)
{
x = xIn;
} // insert
}
public class Swapping
{
// swap: pass references to objects
static void swap(MyInteger rWrap, MyInteger sWrap)
{
// interchange values inside objects
int t = rWrap.getValue();
rWrap.insertValue(sWrap.getValue());
sWrap.insertValue(t);
}
public static void main(String[] args)
{
int a = 23, b = 47;
System.out.println("Before. a:" + a + ", b: " + b);
MyInteger aWrap = new MyInteger(a);
MyInteger bWrap = new MyInteger(b);
swap(aWrap, bWrap);
a = aWrap.getValue();
b = bWrap.getValue();
System.out.println("After. a:" + a + ", b: " + b);
}
}

FUNCTION POINTERS
DEFINITION:
A function pointer is a variable that stores the address of a function that can later be called through that function pointer. This is useful because functions encapsulate behavior. For instance, every time you need a particular behavior instead of writing out a bunch of code, all you need to do is call the function. But sometimes you would like to choose different behaviors at different times in essentially the same piece of code.A function pointer always points to a function with a specific signature! Thus all functions, you want to use with the same function pointer, must have the same parameters and return-type!
There are 2 types of function pointers:
1.Pointers to ordinary C functions or to static C++ member functions.
2.Pointers to non-static C++ member functions.
The basic difference is that all pointers to non-static member functions need a hidden argument.
SYNTAX:
void (*foo)(int);
foo is a pointer to a function taking one argument, an integer, and that returns void. It's similar to declaration of a function called "*foo", which takes an int and returns void. If *foo is a function, then foo must be a pointer to a function.
INITIALIZING:
To initialize a function pointer, the address of a function in program must be given to it. The syntax is like any other variable:
You can get the address of function simply by naming it.
void foo();
func_pointer = foo;
or by prefixing the name of the function with an ampersand
void foo();
func_pointer = &foo;
INVOKING:
Invoke the function pointed similar to calling a function.
func_pointer( arg1, arg2 );
COMPARING FUNCTION POINTERS:
The comparison-operators (==, !=) are used to compare function pointers.
USES:
1. Functions as Arguments to Other Functions
2.Callback Functions
BENEFITS:
• Function pointers provide a way of passing around instructions for how to do something
• You can write flexible functions and libraries that allow the programmer to choose behavior by passing function pointers as arguments
• This flexibility can also be achieved by using classes with virtual functions.
Tuesday 6 March 2012
JAVA COMPILATION PROCESS
Java code does not compile to native code that the operating system executes on the CPU, rather the result of Java program compilation is intermediate bytecode. This bytecode runs in the virtual machine.
Java requires each class to be placed in its own source file, named with the same name as the class name and added suffix .java. This basically forces any medium sized program to be split in several source files. When compiling source code, each class is placed in its own .class file that contains the bytecode. The java compiler differs from gcc/g++ in the fact that if the class you are compiling is dependent on a class that is not compiled or is modified since it was last compiled, it will compile those additional classes. After compiling all source files, the result will be at least as much class files as the sources, which will combine to form Java program. This is where the class loader comes into picture along with the bytecode verifier - two unique steps that distinguish Java from languages like C/C++.
The class loader is responsible for loading each class bytecode. Java provides developers with the opportunity to write their own class loader, which gives developers great flexibility. One can write a loader that fetches the class from everywhere.
STEPS TAKEN BY A LOADER TO LOAD A CLASS:
When a class is needed by the JVM the loadClass(String name, Boolean resolve); method is called passing the class name to be loaded. Once it finds the file that contains the byte code for the class, it is read into memory and passed to the defineClass. If the class is not found by the loader, it can pass the loading to a parent class loader or try to use findSystemClass to load the class from local file system. The Java Virtual Machine Specification is vague on the subject of when and how the Byte Code verifier is invoked, but by a simple test we can infer that the defineClass performs the bytecode verification. The verifier does four passes over the bytecode to make sure it is safe. After the class is successfully verified, its loading is completed and it is available for use by the runtime.
The nature of the Java byte code allows people to easily decompile class files to source. In the case where default compilation is performed, even variable and method names are recovered.
Friday 10 February 2012
OPERATOR PRECEDENCE
Java has well-defined rules for specifying the order in which the operators in an expression are evaluated when the expression has several operators.
Precedence Order: When two operators share an operand the operator with the higher precedence goes first.
Associativity: When two operators with the same precendence the expression is evaluated according to its associativity. That is associativity of an operator is a property that determines how operators of the same precedence are grouped.
The table below shows all Java operators from highest to lowest precedence, along with their associativity.
Operator
|
Description
|
Associativity
|
[]
. () ++ -- |
access array
element
access object member invoke a method post-increment post-decrement |
left to right
|
++
-- + - ! ~ |
pre-increment
pre-decrement unary plus unary minus logical NOT bitwise NOT |
right to left
|
()
new |
cast
object creation |
right to left
|
*
/ % |
multiplicative
|
left to right
|
+ -
+ |
additive
string concatenation |
left to right
|
<<
>>
>>> |
shift
|
left to right
|
< <=
>= >
instanceof
|
Relational
Type comparision
|
left to right
|
==
!= |
Equality
|
left to right
|
&
|
bitwise AND
|
left to right
|
^
|
bitwise XOR
|
left to right
|
|
|
bitwise OR
|
left to right
|
&&
|
conditional AND
|
left to right
|
||
|
conditional OR
|
left to right
|
?:
|
conditional
|
right to left
|
== += -=
*= /=
%=
&= ^=
>>= <<=
>>>=
|
assignment
|
Right to left
|
Order of evaluation: In Java, the left operand is always evaluated before the right operand. Also applies to function arguments.
Short circuiting: When using the conditional AND and OR operators (&& and ||), Java does not evaluate the second operand unless the first argument does not suffice to determine the value of expression.
Monday 6 February 2012
cc OPTIONS
SYNTAX:
Option
|
cc <option>
Description
|
||||||||||||
-c
|
Compiles only; does not attempt to link
source files.
|
||||||||||||
-D name[=value]
|
Is passed to C compiler to assign the
indicated value to the
symbol name
when the C preprocessor is run.
|
||||||||||||
-f float
|
Specifies the floating point options that
the compiler and
linker use. The following
should be supported:
-f - - no floating point required
-f - emulated floating point -fp hardware floating point
(using 80x87 coprocessor)
|
||||||||||||
-Idir
|
Search dir for included files whose names
do not begin with a
slash (/) prior to
searching the usual directories. The
directories for
multiple -I options are
searched in the order specified.
The preprocessor
first searches for
#include files in the directory
containing sourcefile, and
then in
directories named with -I options
(if any), then /usr/ucbinclude,
and
finally, in /usr/include.
|
||||||||||||
-Ldir
|
Add dir to the list of directories
searched for libraries by
/usr/ccs/bin/ucbcc. This option is
passed to /usr/ccs/bin/ld and /usr/lib.
Directories specified with this option
are searched before /usr/ucblib
and
/usr/lib.
|
||||||||||||
-l library
|
If linking, adds the indicated library to
the list of
libraries to be linked.
|
||||||||||||
-M
|
If linking, creates a map file with the
same base name as the
output
executable, but with the suffix.map. This
map file
contains a list of symbols with
their addresses.
|
||||||||||||
-m model
|
Specifies the memory model that the
compiler and linker use.
The models
may include:
|
||||||||||||
-o output
|
If linking, places the executable output
in the file output.
|
||||||||||||
-S
|
Produces assembler listing with source
code.
|
||||||||||||
-Uname
|
Is passed to the C compiler, to undefined
the symbol name.
|
||||||||||||
-Y P, dir
|
Change the default directory used for
finding libraries.
|
Subscribe to:
Posts (Atom)